
No obstante, con la llegada de herramientas asistidas por inteligencia artificial, está cambiando el potencial para optimizar la forma en que se estructuran y utilizan los datos en la suscripción. Los modelos de IA generativa pueden consolidar y organizar información compleja, haciéndola más accesible y utilizable.
Pero esto nos lleva a preguntarnos: ¿Cómo se comparan estos avances con los métodos tradicionales… y qué implican para el futuro de la suscripción?
Basándose en la colaboración entre RGA y DigitalOwl, este artículo analiza casos de uso reales para examinar las oportunidades y los desafíos de aprovechar la inteligencia artificial en la estructuración y presentación de datos de suscripción.
Tres enfoques para la suscripción
Analicemos un caso de suscripción: una mujer de 71 años con antecedentes de ansiedad, depresión, diabetes tipo 2 y dolor crónico que requiere medicación opioide. Al revisar su expediente, determinamos que, si bien su diabetes estaba bien controlada, su depresión había empeorado y se asociaba con ansiedad concurrente; además, había comenzado recientemente un nuevo tratamiento, como se muestra en las imágenes a continuación.
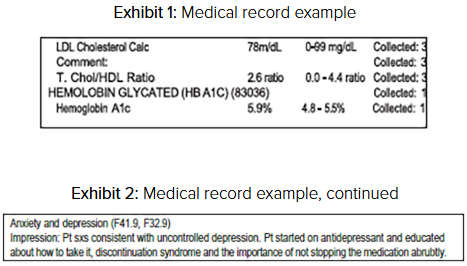
Con esta información, el suscriptor pudo evaluar con precisión el riesgo de la solicitante. Sin embargo, este expediente de suscripción tenía un total de aproximadamente 433 páginas, incluyendo la solicitud, el examen paramédico, los análisis de laboratorio y los historiales médicos que detallaban sus antecedentes clínicos.
Gracias a la colaboración entre RGA y DigitalOwl, los suscriptores ahora tienen acceso a modelos de IA generativa que agilizan el proceso mediante la creación de resúmenes en PDF. Estos resúmenes transforman expedientes extensos, como este caso de 433 páginas, en un formato más conciso y accesible, como se muestra en el Gráfico 3.
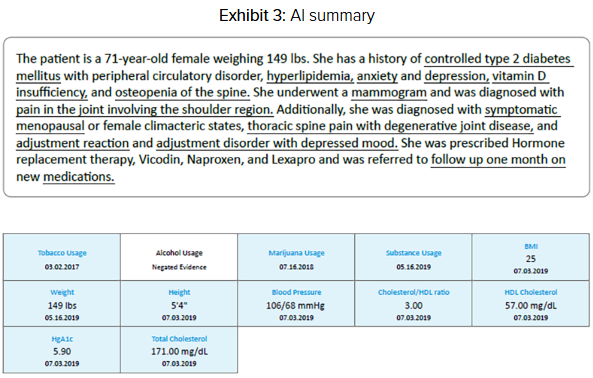
La información duplicada que antes se encontraba dispersa en múltiples secciones del expediente de suscripción ahora se presenta en un formato conciso y accesible para el suscriptor. Esto permite al suscriptor navegar estratégicamente y de forma lógica por los hallazgos médicos del solicitante, lo que facilita evaluaciones de riesgo más eficientes y seguras.
¿Y qué pasa con los datos?
La capacidad de la IA generativa para estructurar hallazgos médicos y diagnósticos permite que la información contenida en cada expediente de suscripción sea fácilmente interpretable en distintos contextos y formatos.
Por ejemplo, además de los resúmenes en PDF, DigitalOwl genera archivos de salida en formato Excel y archivos JSON legibles por máquinas a nivel de caso. Su tecnología DATA API permite llevar el análisis a un nivel más profundo, ya que posibilita a los usuarios recuperar grandes volúmenes de datos estructurados mediante llamadas API basadas en ítems médicos, menciones y otros criterios.
Para los clientes que requieren salidas personalizadas para procesamiento por lotes, existen dos soluciones clave disponibles:
- Customized Tabular Worksheet (CTW): Desarrollada en colaboración con RGA, este formato consolida información seleccionada en una estructura tabular adaptada a las necesidades específicas de cada cliente.
- Post Issue Audit (PIA): Basado en la filosofía de suscripción del cliente, este informe en formato Excel resume los hallazgos más relevantes. En los próximos meses, se prevé que la Triage Tool de DigitalOwl —una nueva solución de auditoría impulsada por inteligencia artificial— complemente su actual informe PIA.
El archivo de salida en Excel que se muestra a continuación contiene la misma información previamente resumida en el formato PDF. Sin embargo, ahora está organizada por afecciones relevantes, fechas en que ocurrieron dichas afecciones e incluso el nivel de gravedad potencial, según lo determinado por la configuración del modelo de IA.
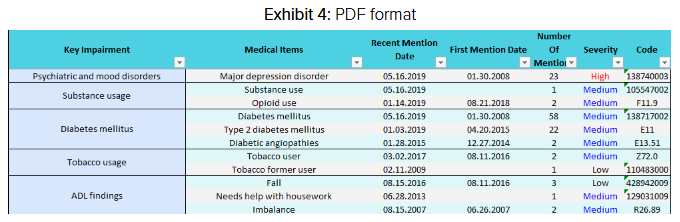
Gracias a la capacidad de clasificar de forma sistemática diversos “ítems médicos”, los suscriptores ahora pueden priorizar los hallazgos médicos según su relevancia y gravedad. Además de los ítems médicos mencionados anteriormente, el archivo de salida en Excel también incluye la siguiente información:
- Un resumen general del caso
- Información biométrica, como estatura, peso y presión arterial, con referencias de página a la fuente original
- Detalles de los profesionales o centros relacionados con los ítems médicos listados
- Resultados de laboratorio con nombres de pruebas y fechas de realización
- Una lista de medicamentos, incluyendo fechas de surtido de las recetas
Esta visión general representa solo la superficie de lo que es posible. Al explorar más a fondo los datos contenidos en estos archivos, surgen nuevos caminos que conducen a oportunidades previamente inexploradas.
Por ejemplo, el mismo historial de depresión detallado en los registros médicos y resumido en el PDF también puede encontrarse en el formato JSON legible por máquina, como se muestra en el Gráfico 5. Gracias a la capacidad de la IA generativa para categorizar cada hallazgo médico, también se proporcionan todos los posibles códigos médicos asociados, como LOINC, ICD-10, SNOMED, entre otros.
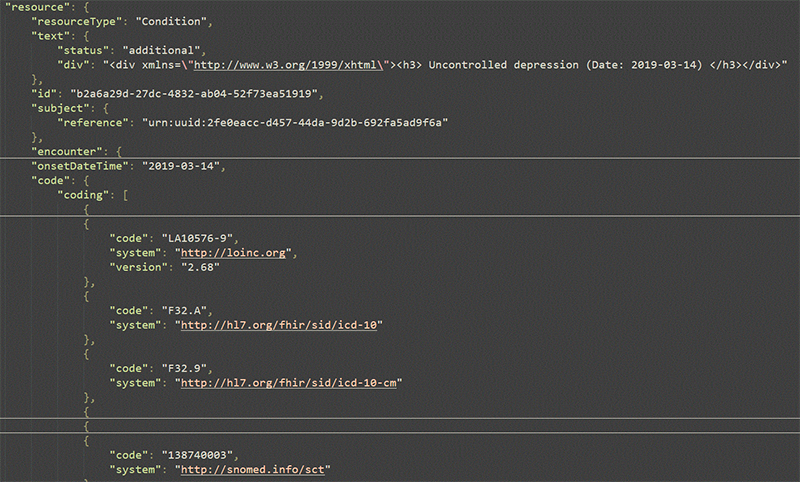
Organizar estas afecciones y hallazgos de esta manera permite introducir los datos en diversos motores de reglas o modelos de gravedad, agilizando así la toma de decisiones en la suscripción. En otras palabras, la misma información que antes requería que un suscriptor revisara manualmente un expediente de más de 400 páginas, ahora puede ser interpretada por un motor de reglas.
Bajo la superficie
Está claro que el análisis de afecciones se ha vuelto más sencillo y eficiente con la integración de la inteligencia artificial. Pero, una vez más, apenas estamos comenzando a explorar el potencial de contar con datos consolidados y organizados.
Tomemos como ejemplo los datos de laboratorio. Dada la variedad de fuentes en las que se presentan los resultados —ya sea a través de paneles de seguros, datos de terceros, historiales médicos electrónicos o informes del médico tratante—, los suscriptores deben revisar con frecuencia cada valor de laboratorio de forma aislada, según su fuente correspondiente. Este proceso puede resultar tedioso, ya que requiere que el suscriptor reconstruya los resultados para estimar la mortalidad en función de hallazgos recientes, tendencias o promedios.
Sin embargo, gracias a la capacidad de la IA generativa para reestructurar todos los hallazgos de laboratorio, ahora podemos desarrollar lógicas basadas en reglas mucho más integrales. Las siguientes capturas muestran cómo pueden categorizarse, filtrarse y evaluarse las pruebas de laboratorio, independientemente de su fuente.
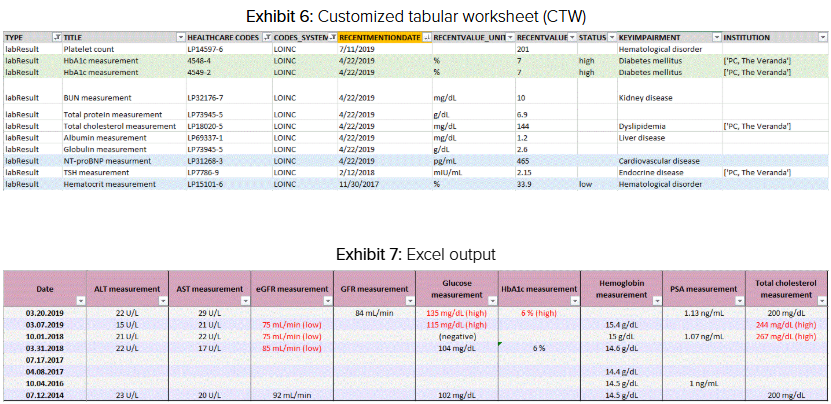
Ya sea utilizando una hoja de cálculo tabular personalizada o una salida específica en Excel, los suscriptores ahora pueden consolidar los resultados de laboratorio provenientes de todas las fuentes disponibles en un formato simplificado. Esta consolidación ofrece oportunidades significativas:
Análisis preciso de pruebas de laboratorio poco comunes- Los suscriptores ahora pueden analizar pruebas de laboratorio menos frecuentes provenientes de diversas fuentes. Por ejemplo, el análisis de NT-proBNP es más común en los paneles de seguros, mientras que los resultados de un hemograma completo (CBC) suelen encontrarse en historiales médicos o datos de terceros, como se muestra en azul en el CTW del Anexo 6. Anteriormente, esto requería cotejar manualmente los resultados dentro de los documentos fuente correspondientes. Al consolidar todos los hallazgos de laboratorio y los resultados relevantes —independientemente del texto fuente— los suscriptores tienen menos probabilidades de pasar por alto o descartar un hallazgo potencialmente significativo que merezca atención.
Análisis de tendencias simplificado
Los análisis de tendencias, como las pruebas de glucosa mostradas en la salida de Excel del Anexo 7, ahora son mucho más sencillos. Los suscriptores pueden examinar todos los valores de una prueba específica, sin importar la fuente de donde provienen. Esta capacidad resulta sumamente valiosa, especialmente cuando los resultados de las pruebas suelen estar dispersos en archivos de evaluación de riesgos más extensos.
Revisión de hallazgos recientes en todos los requisitos- Las salidas consolidadas permiten a los suscriptores revisar hallazgos recientes provenientes de todos los requisitos de suscripción de manera simultánea. El formato Excel organiza automáticamente los datos por fecha, mientras que el CTW resalta la “fecha de mención reciente” (marcada en naranja en el Anexo 6), que indica los resultados más actuales. Esta funcionalidad se aplica tanto a afecciones médicas como a pruebas diagnósticas, proporcionando al suscriptor una vista clara y ordenada de los hallazgos según su gravedad y fecha.
Además, categorizar estos hallazgos por “afecciones clave” y asociarlos con códigos relevantes —como la prueba de A1c destacada en verde en el Anexo 6— mejora la consolidación de datos. Esto permite desarrollar reglas específicas para cada afección o modelos de severidad. Al consolidar todos los datos de suscripción, los suscriptores obtienen la capacidad de organizar la información relevante de forma lógica, dinámica y accesible, desbloqueando un abanico de posibilidades.
En esencia, el valor de los datos estructurados radica en su organización. Al presentar la información en un formato intuitivo y fácil de consumir, los datos estructurados permiten a los suscriptores tomar decisiones más precisas, eficientes e informadas.
Oportunidades y consideraciones
Al igual que los resúmenes en PDF, los datos estructurados son simplemente una forma de presentar los resultados de un modelo de inteligencia artificial generativa. Por lo tanto, las preocupaciones sobre la precisión de los modelos de IA también aplican a los datos estructurados que producen.
La validación de estos datos es fundamental. Por ejemplo, el modelo puede malinterpretar u omitir hallazgos médicos, especialmente cuando los datos de entrada son complejos o poco claros. Los Anexos 8 y 9 ilustran un caso en el que el modelo identificó erróneamente a una persona como paciente con diabetes mellitus. Una investigación más profunda reveló que se trataba únicamente de un código de diagnóstico utilizado para solicitar una prueba de glucosa, cuyo resultado fue normal. Sin embargo, este diagnóstico erróneo de diabetes se propagó en todos los formatos de datos estructurados.

El Anexo 10 resalta otro desafío: La enfermedad de Crohn de un paciente fue omitida porque el modelo de inteligencia artificial generativa no pudo interpretar de manera confiable los detalles escritos a mano. Como resultado, todos los formatos de datos estructurados omitieron la mención del historial de enfermedad de Crohn del paciente.

La presentación de afecciones médicas o hallazgos diagnósticos en formato estructurado conlleva desafíos únicos
Por ejemplo, si bien el Anexo 6 destaca los beneficios significativos de la hoja de cálculo personalizada para la consolidación de datos, existen numerosos casos en los que campos como “Institución” aparecen vacíos. Los suscriptores deben evaluar la relevancia y fiabilidad de las evaluaciones según la fuente de información. Aún se requiere una mayor precisión en los modelos de IA generativa para identificar y asociar correctamente los hallazgos médicos con sus fuentes exactas.
Estos desafíos surgen de los esfuerzos continuos por validar los datos estructurados en función de los resúmenes en PDF y de la capacidad del suscriptor para revisarlos. Los resúmenes en PDF de DigitalOwl incluyen hipervínculos a los datos fuente, lo que permite a los suscriptores verificar la legitimidad de la información. Esto les permite rastrear las afecciones hasta sus fuentes originales y evaluar qué condujo al “diagnóstico” de dicha condición, como se muestra en el ejemplo de diabetes en los Anexos 8 y 9.
La consistencia y precisión en los datos estructurados son esenciales
Esto no solo es fundamental para una adecuada gestión del riesgo en suscripción, sino también para fines de auditoría y adjudicación de reclamaciones.
A medida que la IA generativa continúa evolucionando - Ya sea aplicada a flujos de trabajo de suscripción o a notas de casos —como aquellas generadas por DigitalOwl— la necesidad de contar con mejores herramientas y técnicas de validación se volverá crítica para el avance del análisis de datos estructurados y la evaluación del riesgo.
Con una validación y perfeccionamiento continuos, los desafíos de garantizar la precisión y generar confianza en los datos estructurados por IA irán disminuyendo gradualmente. Una vez superados estos obstáculos, se ampliarán las oportunidades para la consolidación de datos estructurados y el desarrollo de reglas, transformando lo que antes parecía una inevitabilidad lejana en una realidad actual llena de posibilidades.
Y este es solo el comienzo.
Contáctanos para saber más sobre cómo RGA y DigitalOwl están liderando la transformación de los flujos de trabajo de suscripción mediante inteligencia artificial, impulsando una mayor eficiencia y decisiones de riesgo más acertadas.



