
Twitter ofrece al público la oportunidad de dar su opinión, en tiempo real, sobre los acontecimientos mundiales mediante la publicación de textos breves denominados ‘tweets’.
La pandemia de COVID-19 fue el evento definitorio de 2020, lo que lo convierte en un excelente tema para el análisis de sentimiento: el uso del procesamiento del lenguaje natural para determinar automáticamente la emoción que expresa quien escribe un texto o tweet. Queríamos ver si podíamos usar los datos de Twitter relacionados con la COVID-19 en el Reino Unido para descubrir información relevante para el interés público y la industria de seguros.
De los datos no estructurados a la predicción de sentimientos
Twitter es una mina de oro de macrodatos que involucra a más de mil millones de cuentas de usuario, las cuales generan alrededor de 500 millones de tweets diarios, aproximadamente 200 billones de tweets por año. Estos datos vienen con desafíos, como el uso de un lenguaje no convencional, sesgos potenciales y un tiempo de procesamiento prolongado. También hay una serie de pasos involucrados en preparar los datos, construir los modelos y realizar predicciones de sentimientos.
Paso 1: Preparar los datos
Los desarrolladores pueden acceder abiertamente a los datos de Twitter a través de la interfaz de programación de aplicaciones (API) de Twitter. Utilizamos los números de identificación (ID) de Twitter del 1° de enero al 22 de noviembre de 2020, los cuales fueron publicados en el estudio ‘Conjunto de datos de chat de Twitter COVID-19 para uso científico’ del Panacea Lab de la Universidad Estatal de Georgia.
Se usó Hydrator de DocNow para extraer (‘hidratar’) los tweets y metadatos originales a través de estos números de identificación. Twitter restringe la tasa de hidratación, por lo que tomamos una muestra del 25 % del conjunto de datos completo y adoptamos un enfoque distribuido para la extracción de datos. Esto resultó en 25 millones de tweets en inglés, para los cuales la hidratación tomaría alrededor de 10 días usando una sola cuenta de Twitter.
Los datos de ubicación del usuario contienen mucho ruido estadístico. Utilizamos técnicas como el mapeo directo, el mapeo semiestructurado y la API de codificación geográfica de Google para obtener 1.7 millones de tweets del Reino Unido.
Paso 2: Entrenar a los modelos de aprendizaje automático
Para el aprendizaje supervisado, se debe asignar una etiqueta de sentimiento a cada tweet. El etiquetado manual requiere mucha mano de obra, por lo que aplicamos un enfoque de clasificación binaria automatizada basado en tweets que contienen emoticones positivos o negativos, etiquetados como “positivos” (por ejemplo, ![]()
![]() ) respectivamente. Solo un pequeño subconjunto de tweets contenía emoticones de sentimientos fuertes. Usamos 7000 tweets etiquetados con emoticonos para el entrenamiento y etiquetamos manualmente 3000 tweets para la prueba, tomados del 1° de enero al 26 de abril de 2020.
) respectivamente. Solo un pequeño subconjunto de tweets contenía emoticones de sentimientos fuertes. Usamos 7000 tweets etiquetados con emoticonos para el entrenamiento y etiquetamos manualmente 3000 tweets para la prueba, tomados del 1° de enero al 26 de abril de 2020.
Agregamos a nuestro conjunto de capacitación el conjunto de datos ‘sentiment140’, un conjunto de datos de Twitter etiquetado como no relacionado con COVID-19; esto llevó nuestro conjunto de entrenamiento enriquecido a 200 000 tweets etiquetados, con igual número de etiquetas positivas y negativas. Esto contribuyó a un vocabulario más amplio que podría mejorar el rendimiento predictivo.
A continuación, llevamos a cabo los pasos de preprocesamiento y codificación que se muestran en la Figura 1. La codificación es el paso de extracción de características que convierte un conjunto de palabras (‘tokens’) en vectores numéricos (‘características’).
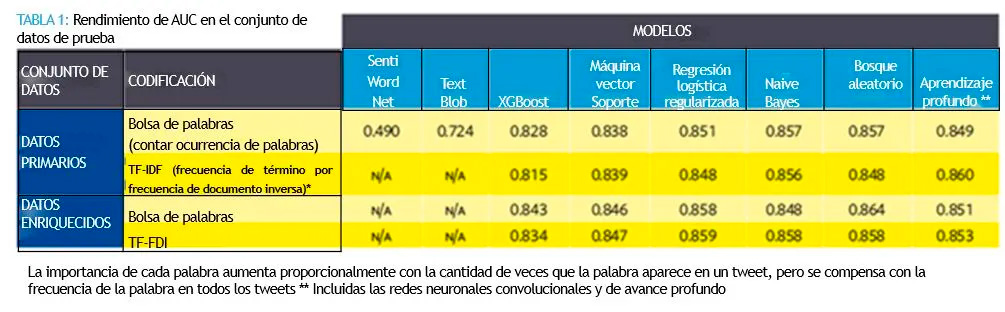
Para cada conjunto de datos, exploramos una variedad de codificaciones y algoritmos de aprendizaje automático para predecir la clasificación binaria de sentimiento positivo (+1) o negativo (-1). La métrica de rendimiento del modelo es el “área bajo la curva ROC” (AUC, por sus siglas en inglés), una medida agregada de rendimiento en todos los umbrales de clasificación. Los comparamos con modelos de línea de base simples: SentiWordNet y TextBlob (herramientas de código abierto listas para su uso inmediato).
Según los resultados de la Tabla 1, el tiempo de ejecución y la simplicidad, nuestro modelo final seleccionado es una regresión logística regularizada con codificación TF-IDF entrenada en el conjunto de datos enriquecido. Esto logró un AUC de 0.859. El ajuste fino de los modelos de aprendizaje automático en un conjunto de datos de Twitter específico de COVID-19 puede superar significativamente a las herramientas de código abierto.
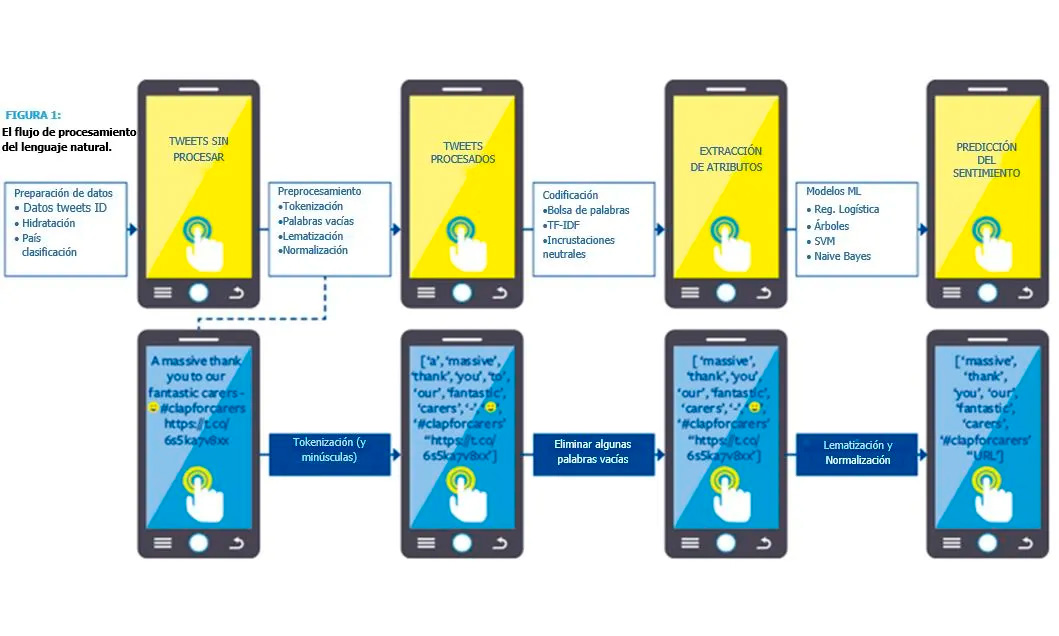
Paso 3: Análisis de sentimiento
Nuestro modelo seleccionado se utilizó luego para asignar puntajes de sentimiento individuales a los 1.7 millones de tweets del Reino Unido. Los puntajes resultantes permiten un mayor análisis de las tendencias generales a lo largo del tiempo, el sentimiento relacionado con temas específicos y los impulsores subyacentes.
Principales preocupaciones relacionadas con el coronavirus
La Figura 2 compara 20 de los temas más populares durante la primera ola versus los correspondientes durante toda la duración de la pandemia. Los temas más importantes incluyen ‘confinamiento’, ‘gobierno’, ‘muertes’, ‘casos’ y ‘salud’.
El Servicio Nacional de Salud (NHS, por sus siglas en inglés) del Reino Unido fue un tema frecuente durante la primera ola, pero no durante los meses siguientes. Se asoció con el sentimiento positivo resultante de la iniciativa ‘aplausos para los cuidadores’, pero hubo descensos en el sentimiento relacionado con los temores sobre la escasez de camas de hospital y equipos de protección personal. La discusión sobre ‘vacunas’, ‘escuela’ y ‘máscaras’ era relativamente poco común durante la primera ola, pero posteriormente se generalizó.
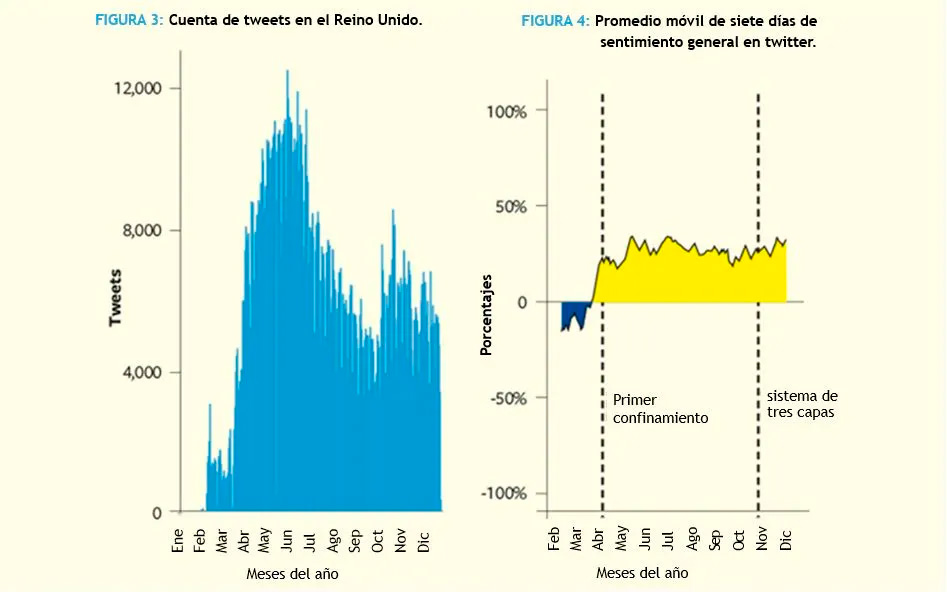
Análisis de sentimiento y tendencia general
Los tuits de febrero se centraron en el desarrollo de la COVID-19 en otros países y transmitieron un sentimiento más negativo. A partir del punto de inflexión a mediados de marzo, el sentimiento general se ha mantenido positivo durante el resto del año. El sentimiento hacia el primer confinamiento fue en general positivo.
La granularidad de los datos de texto nos permite realizar un análisis temático más profundo al analizar el sentimiento y el contexto en torno a ciertas palabras. Veremos dos ejemplos aquí: las palabras ‘gobierno’ y “seguros’.
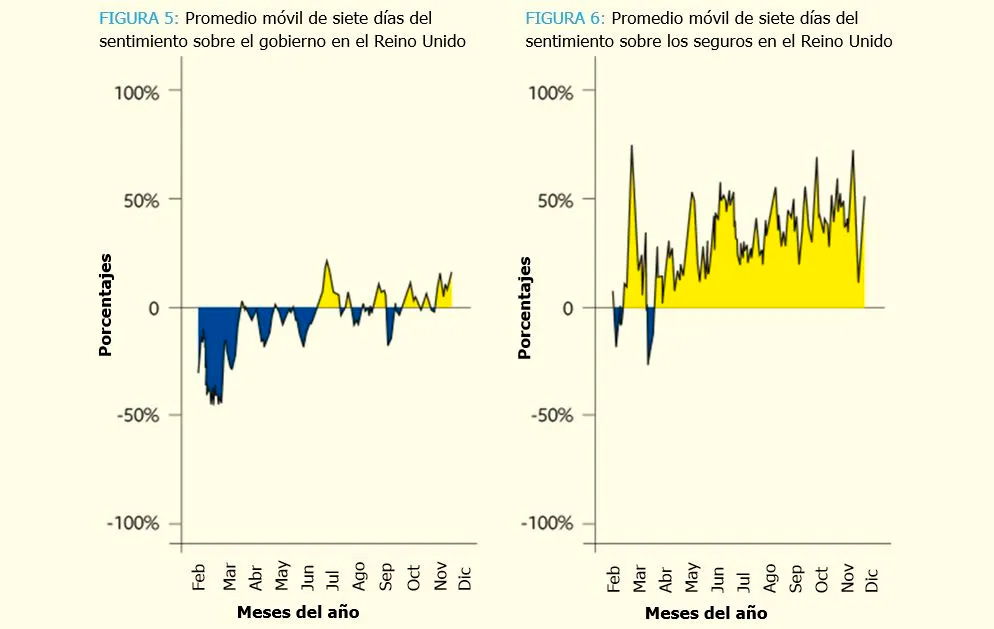
La Figura 5 muestra que el sentimiento sobre el gobierno fue bajo durante la primera ola, pero mejoró y se mantuvo neutral de abril a noviembre. Estas tendencias son ampliamente consistentes con el estudio social COVID-19 del University College London, un estudio de panel de más de 70 000 encuestados, realizado a través de encuestas semanales en línea. El análisis de sentimiento de las redes sociales puede ser una herramienta rentable para analizar la evolución de la opinión pública; las encuestas tradicionales pueden sufrir de menor cobertura y retrasos. Sin embargo, existen sesgos potenciales relacionados con la demografía de los usuarios de las redes sociales en comparación con la población en general.

Sentimientos sobre seguros y aseguradoras
La Figura 6 muestra un gran pico en febrero debido a un aumento en los tweets acerca de consejos sobre seguros de viaje. La caída de marzo antes del confinamiento se debió principalmente a los consejos del gobierno, que pedían al público que se mantuviera alejado de los bares y restaurantes sin hacer cumplir los cierres, lo que dejaba a las empresas en la imposibilidad de reclamar un seguro y expuestas a la quiebra.
Muchas aseguradoras son percibidas negativamente debido a las reclamaciones y pérdidas relacionadas con la COVID-19, la interrupción del negocio, la cancelación de eventos, las disputas legales, la mala gestión de fondos y los recortes en dividendos. Por el contrario, NFU Mutual, Admiral, Vitality y Cigna son ejemplos de aseguradoras con un sentimiento favorable gracias a su servicio al cliente, reembolsos de pólizas de automóviles y resiliencia financiera. Es alentador ver una actitud positiva hacia el servicio al cliente y los consejos de las aseguradoras sobre salud mental, ejercicio y cultura laboral; estas acciones podrían ser emuladas por otras aseguradoras por el bien de la sociedad.
Análisis de sentimiento en la industria de seguros
Las aseguradoras podrían aprovechar el análisis de sentimiento y las redes sociales en su proceso de transformación digital. Las tendencias se pueden identificar a partir del análisis de la ‘voz del cliente’, lo que lleva a la propuesta de valor. Por ejemplo, la pandemia podría impulsar la demanda de productos de protección, seguros basados en el uso y seguros para bicicletas.
Adicionalmente, el análisis de sentimiento de Twitter es útil para la gestión de la reputación, ya que permite a las aseguradoras monitorear la opinión pública de sus organizaciones, productos o campañas de marketing.
Estudios como ‘El lenguaje psicológico en Twitter predice la mortalidad por enfermedades cardíacas a nivel de condado’ (Eichstaedt et al., 2015) y ‘Correlación del lenguaje de Twitter con los resultados de salud a nivel comunitario’ (Schneuwly et al., 2019) han encontrado que el lenguaje en Twitter está correlacionado con los resultados de mortalidad y morbilidad, como enfermedades cardíacas, diabetes y cáncer. Inevitablemente, esto sugiere una posible aplicación en suscripción y fijación de precios. Sin embargo, esta aplicación requeriría controles rigurosos en torno a las consideraciones éticas y de privacidad, y el análisis de los efectos de correlación versus causalidad.
No obstante, estos métodos tienen aplicaciones prometedoras en toda la cadena de valor de los seguros, incluido el desarrollo de productos, las ventas, el marketing, el análisis de la competencia, la elaboración de perfiles sociales y, en última instancia, la prestación de mejores servicios a los clientes.
Reimpreso con permiso de © 2020 The Actuary and the Institute and Faculty of Actuaries by Redactive Publishing Limited [El Actuario y el Instituto y Facultad de Actuarios por Publicación redactiva limitada].









